capybaraで取得した要素の中身を確認する
テストが通らない原因を探るため、binding.pryを仕込んでデバッグをしておりました。
止まってくれたところで、
find(‘#client_check_by_id’)
とすれば、その要素を取得は出来るものの、その中身を見たい!と思い、そのやり方を調べてみました。
[1] pry(#<RSpec::ExampleGroups::Nested::Nested_2>)> find('#client_check_by_id')
=> #<Capybara::Node::Element tag="select" path="/html/body/main/form/div[1]/div[10]/select">
以下のように、
find(‘#client_check_by_id’).native.to_s
としてあげると、中身の要素を見ることが出来ました!!
[2] pry(#<RSpec::ExampleGroups::Nested::Nested_2>)> find('#client_check_by_id').native.to_s
=> "<select class="select required" name="client[check_by_id]" id="client_check_by_id"><option value=""></option> <option value="1">user 1</option> <option value="3">user 3</option> <option value="5">user 5</option> <option value="7">user 7</option></select>"
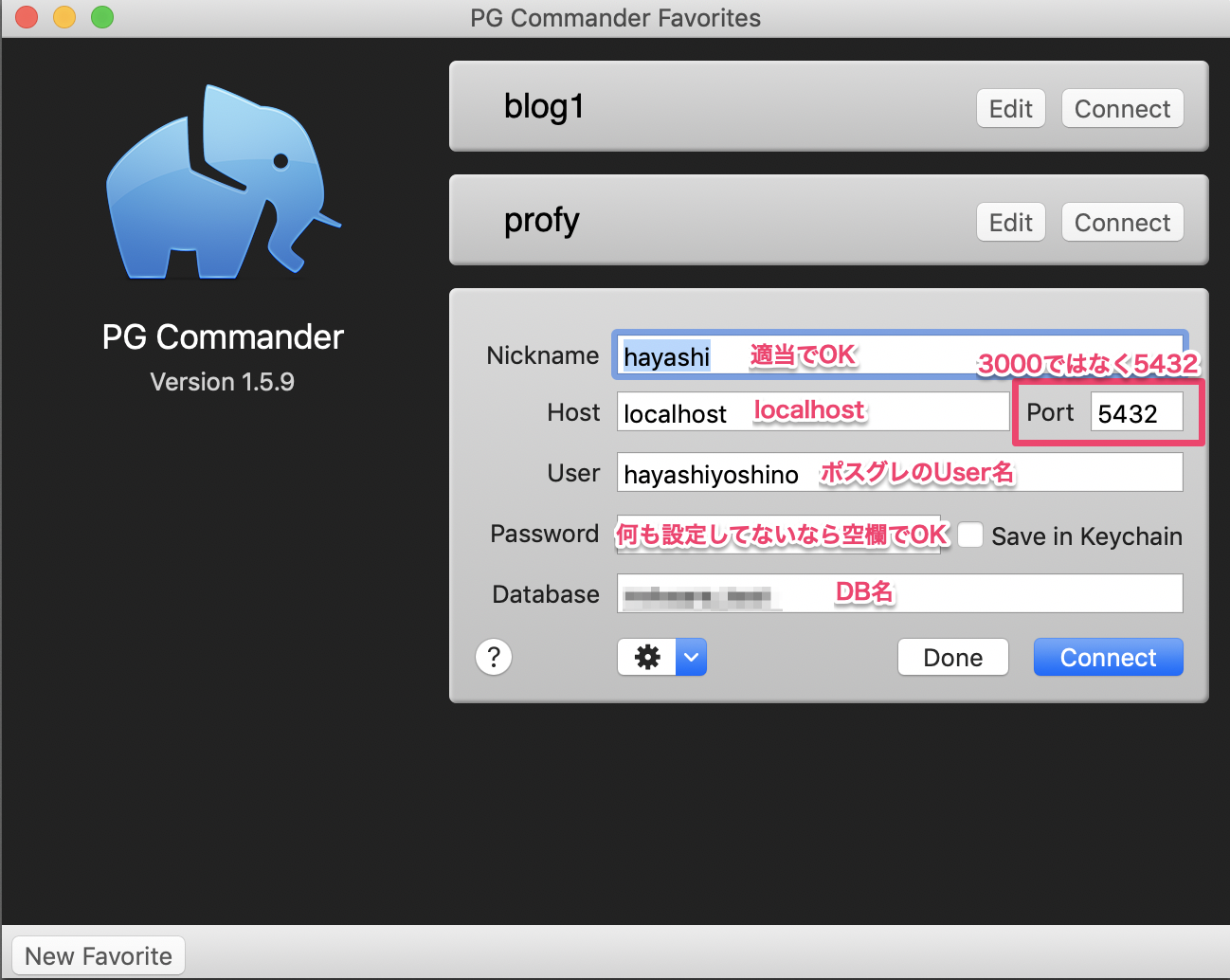
Heroku本番DBの内容をローカルに持ってくる
Herokuの本番DBの内容をローカルに持ってくる方法を教えていただきました!!
これは便利!!と感動したくので書き留めておきます。
以下のように、
heroku pg:pull herokuのDB名 ローカルDB名 --app アプリ名
とすると取得できます。
$ heroku pg:pull herokuのDB名 ローカルDB名 --app アプリ名
heroku-cli: Pulling herokuのDB名 ---> ローカルのDB名
pg_dump: last built-in OID is xxxx
pg_dump: reading extensions
pg_dump: identifying extension members
pg_dump: reading schemas
pg_dump: reading user-defined tables
pg_dump: reading user-defined functions
pg_dump: reading user-defined types
pg_dump: reading procedural languages
pg_dump: reading user-defined aggregate functions
pg_dump: reading user-defined operators
pg_dump: reading user-defined access methods
pg_dump: reading user-defined operator classes
pg_dump: reading user-defined operator families
pg_dump: reading user-defined text search parsers
pg_dump: reading user-defined text search templates
pg_dump: reading user-defined text search dictionaries
pg_dump: reading user-defined text search configurations
pg_dump: reading user-defined foreign-data wrappers
pg_dump: reading user-defined foreign servers
.
.
.
.
略
heroku-cli: Pulling complete.
これだけでデータをローカルに引っ張ってこれました!!
Heroku便利&教えてもらえてよかったです!!
テストDBだけリセットしたい(postgresql)
テストデータベースだけリセットしたい!と思うことがありました。
調べてみたところ、以下の手順でテストデータベースをリセットできるようでした!
①データベースをtestに切り替える
②データベースを消す
$ bundle exec rake db:drop RAILS_ENV=test
Dropped database 'm4ware_test'
③データベースを作り直す
$ bundle exec rake db:create RAILS_ENV=test
Created database 'm4ware_test'
④スキーマを読み込んでテーブルを作り直す
$ bundle exec rake db:schema:load RAILS_ENV=test
-- enable_extension("plpgsql")
-> 0.0900s
-- create_table(".................略
これでスッキリtest環境のDBのみリセットすることができました!
database_cleaner等のgemを入れたほうがいいという記事も何個か見かけましたが、プロジェクトをあまりいじらずに自分の環境だけリセットしたかったので今回はこの方法が良い感じでした!
おまけ
test環境でコンソールを動かすときは以下のコマンドで立ち上がります!
bin/setup
先週末で自分が関わっていたプロジェクトが無事終了し、本日から新しいプロジェクトに関わることになりました!
その環境構築をしている中で、bin/setupコマンドを実行することがありました。
bin/setupが何なのかよくわかっていなかったので調べてみることにしました。
bin/setupとは
bin/setupとは、Railsアプリ配下にあるbin/setupファイルの内容を実行するコマンドです。
アプリケーションを初期化するスクリプトが置かれます。
ここにセットアップ内容を書いておくと、新しく環境構築するのがとても楽になります。
(実際とても楽でした)
そもそもbinディレクトリとは
bundle, rails, rake, setup, spring, update, yarnファイルが入っております。
それぞれ、サーバーを起動したり、セットアップ内容を書いておいたり等、アプリケーションを管理するためのスクリプトファイルです。
その他感想
前回のプロジェクトをDockerで環境構築した時も思ったのですが、こういったコマンド1つで設定が実行できるものがあると本当に楽ちんです!
利用するだけではなく、自分もこういった設定ファイルを作れるようになりたいと思います!
また、bin/setupについて調べていた際、以前もリンクを貼らせていただいた以下のスライドが出てきたので再び読み返してみました。
「一般的でなくても、使うときによりeasyになるなら取り入れていく姿勢」
「楽をするための努力を惜しまない」
というのを自分の中でも”当たり前”にしていきたいと思います。
新しいプロジェクトも頑張る!!!
意味のあるテストデータの作成
FactoryBotを使ったデータ作成について基礎を理解したいと思うことが多々ありました。
Everyday Rails Rspec 第4章、「意味のあるテストデータの作成」についてまとめる機会を頂いたので、こちらに下書きを書いていきたいと思います!
内容
・ファクトリ対フィクスチャ
・FactoryBotをインストールする
・アプリケーションにファクトリを追加する
・シーケンスを使ってユニークなデータを生成する
・ファクトリで関連を扱う
・ファクトリ内の重複をなくす
・コールバック
・ファクトリを安全に使うには
・まとめ
ファクトリ対フィクスチャ
フィクスチャのメリット
フィクスチャは比較的速い
Railsに最初から付いてくる
フィクスチャのデメリット
テストとは別のフィクスチャファイルに保存された値を覚えておく必要がある
フィクスチャはもろくて壊れやすい(らしい)
Railsはフィクスチャのデータを作るときActive Recordを読み込まない
・・・このような理由からテストデータのセットアップが複雑になってきたときはファクトリがおすすめ
ファクトリはシンプルで柔軟性に富んだテストデータ構築用のブロック
ファクトリは適切に(つまり賢明に)使えば、あなたのテストをきれいで読みやすく、リアルなものに保ってくれる
多用しすぎると遅いテストの原因になる(らしい)
FactoryBotをインストールする
group :development, :test do ~ end の中にgem 'factory_bot_rails'を追加し、bundle installします
group :development, :test do
略
gem 'factory_bot_rails'
略
end
アプリケーションにファクトリを追加する
spec/factorys/users.rbに属性や値を書いていきます
spec/factorys/users.rb
FactoryBot.define do
factory :user do
name 'hayashi'
email "test@gmail.com"
password '11111111'
end
end
このような設定をしておくだけで、テスト内で FactoryBot.create(:user) と書くと、定義したuserのデータが生成されます。
spec/models/user_spec.rb
require 'rails_helper'
describe 'User' do
it '有効なファクトリを持つ事' do
expect(FactoryBot.create(:user)).to be_valid
end
end
end
一方、FactoryBotを使用せず書くと、以下のようになります。
spec/models/user_spec.rb
require 'rails_helper'
describe 'User' do
it '有効なファクトリを持つ事' do
user = User.create(
name 'hayashi',
email "test@gmail.com",
password '11111111'
)
actexpect(:user).to be_valid
end
end
end
FactoryBotを使うと簡潔に書くことができる一方、どんな値を持ったデータが生成されているのかテストファイルを直接みるだけではわからないという注意点もあります。
時と場合によって、FactoryBotを使わずデータをベタ書きするのか、FactoryBotを使うのか使い分けるのが良いようです。
シーケンスを使ってユニークなデータを生成する
先ほど作ったファクトリを何回実行しても同じ値を持ったデータが作成されます。
メールアドレスのように、ユニークなデータでないとバリデーションエラーを起こしてしまう物に関しては、シーケンスを使ってユニークなデータを生成してあげることができます。
spec/factorys/users.rb
FactoryBot.define do
factory :user do
name 'hayashi'
sequence(:email) { |n| "test#{n}@gmail.com" }
password '11111111'
end
end
ファクトリで関連を扱う
FactoryBotはアソシエーションを扱うときにとても便利です。
以下のファクトリーはアソシエーション関連にあるデータも作成する設定です。
userモデル、projectモデル、noteモデルがあり、
・userモデルがhas_many :notes、has_many :projectsで、
・projectモデルがbelongs_to :user、has_many :notes
・noteモデルがbelongs_to :user、belongs_to :project
であるデータを作成する際は以下のように作成できます。
spec/factorys/notes.rb
FactoryBot.define do
factory :note do
message 'I am hayashi'
association :project
user {project.owner} // assosiation :user としてしまうと
end userが重複して作られてしまう
end
spec/factorys/projects.rb
FactoryBot.define do
factory :project do
sequence(:name) { |n| "project#{n}" }
association :owner
end
end
spec/factorys/users.rb
FactoryBot.define do
factory :user, aliases: [:owner] do
name 'hayashi'
sequence(:email) { |n| "test#{n}@gmail.com" }
password '11111111'
end
end
あとは、以下のように、FactoryBot.create(:note) とnoteを作成すればOKです。
spec/models/user_spec.rb
require 'rails_helper'
describe 'User' do
it '有効なファクトリを持つ事' do
expect(FactoryBot.create(:note)).to be_valid
end
end
end
ファクトリ内の重複をなくす
ファクトリで、ある属性の値だけ別なファクトリを作りたい時は以下のように設定します。
spec/factorys/projects.rb
FactoryBot.define do
factory :project do
sequence(:name) { |n| "project#{n}" }
due_on 1.week.from_now
association :owner
end
factory :project_due_yesterday, class: Project do
sequence(:name) { |n| "project#{n}" }
due_on 1.day.from_now
association :owner
end
end
こうすれば、
FactoryBot.create(:project)
FactoryBot.create(:project_due_yesterday)
とスペックでファクトリを呼び分けることで違うデータを持ったファクトリを生成することができます。
しかし、これだと、nameやassosiationの部分が重複しています。
この重複を無くした書き方も以下のようにすることで可能です。
spec/factorys/projects.rb
FactoryBot.define do
factory :project do
sequence(:name) { |n| "project#{n}" }
due_on 1.week.from_now
association :owner
factory :project_due_yesterday do // ネストさせた
due_on 1.day.from_now
end
end
end
factory :project の中に factory :project_due_yesterday を入れ子にすることで、重複していたnameやassosiationの記述、class: Projectの記述を省略できます。
また、ファクトリをネストさせる他にも、traitを使った書き方もあります。
spec/factorys/projects.rb
FactoryBot.define do
factory :project do
sequence(:name) { |n| "project#{n}" }
due_on 1.week.from_now
association :owner
trait :due_yesterday do
due_on 1.day.from_now
end
end
end
traitを用いて書いた時、スペックでファクトリを生成する際は、
FactoryBot.create(:project, :due_yesterday)
と引数でtraitを指定します。
コールバック
あるモデルをcreate・newした後、別のモデルも作成したい場合はコールバックを使用します。
コールバックをtraitを用いて書けば、簡単にコールバックを呼んだり呼ばなかったり選択することができます。
spec/factorys/projects.rb
FactoryBot.define do
factory :project do
sequence(:name) { |n| "project#{n}" }
due_on 1.week.from_now
association :owner
trait :with_note do
after(:create){|project| create_list(:note, 5, project: project)}
end
end
end
こうしておくと、FactoryBot.create(:project, with_note) とすればコールバックが実施され、projectの関連先のnoteのデータも作成してくれます。
FactoryBot.create(:project) と通常通りならコールバックは実施されません。
これ以外にも、traitを使えば非常に複雑なデータの作成もスッキリかけるようになります。
ファクトリを安全に使うには
ファクトリを使うとテスト中に予期しないデータが作成されたり、無駄にテストが遅くなったりする原因になります。
(コールバックを使って関連するデータを作成する必要があるなら、ファクトリを使うたびに呼び出されないよう、トレイトの中でセットアップするようにするなど気をつけます。)
まとめ
・ファクトリを使うことで、複雑なデータでもスペック内でスッキリと呼び出すことが可能になります。
・テストは理解しやすいものであることが大切なので、初心者の場合、ファクトリではなくnewやcreateでベタ書きするのもありだよ、と翻訳者の1人である魚さんも言っていました。
・ファクトリの便利さを知れたので、まずは使い方をもっと理解し、パフォーマンスや可読性についても考慮してかけるようになりたいです。
rakeタスクを作る
menuテーブルが持っていたimageカラムの値を、menus_imagesテーブルのimageカラムに移すrakeタスクを作りました。
rakeタスクは初めて作ったので、手順を書き留めておきます。
タスクを生成する
以下のコマンドを打つと、タスクがlib/tasks配下に生成されます。
$ rails g task タスクの名前
今回自分は以下のコマンドを実行しました。
$ rails g task move_to_menu_image
create lib/tasks/move_to_menu_image.rake
タスク内容を定義
実行したい内容を task タスク名 do ~ end の中に定義していきます。
今回自分はmenuテーブルが持っていたimageカラムの値を、menus_imagesテーブルのimageカラムに移したかったので、以下のように書きました。
namespace :move_to_menu_image do
desc "menusテーブルのimageカラムの値をmenu_imagesテーブルに移行する"
task move_menu_image: :environment do
Menu.all.each do |menu|
menu_image = MenuImage.new(menu_id: menu.id, image: menu.image)
menu_image.save
end
end
end
taskを実行
taskを作成したら、そのタスクを実行すれば、定義した通りの内容が実行されます。
以下のコマンドでrakeタスク一覧を確認できます。
$ rake -vT
自分の場合は以下のようなコマンド名でしたので、これを実行しました。
$ rake move_to_menu_image:move_menu_image
これでrakeタスクを作成して無事実行することができました!!
参考文献
以下の記事を参考にさせていただきました!!